Foreword
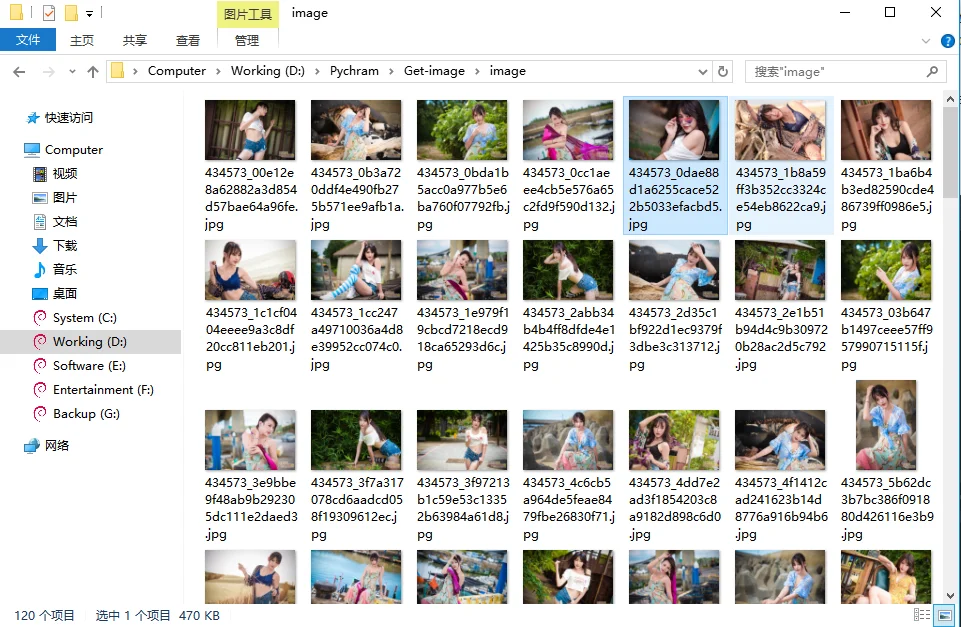
某天,逛到了某社区一帖子,发现帖子里的妹子图片,嗯还蛮不错的。帖子有7页,每页20张图,要是每张都手动下载,那岂不“累死了”?不存在的,祭出py download it。
Main body
初次使用BeautifulSoup,代码不入眼,大佬勿喷~
大体步骤:
1、获取7个页面url
2、获取单个页面里所有图片的url
3、下载所有图片
4、提取文件名并入库保存图片
代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
import requests, os, time
from bs4 import BeautifulSoup
def get_image():
for x in range(1, 7):
url = "http://hongdou.gxnews.com.cn/viewthread-16250447-" + str(x) + ".html"
print(url)
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 UBrowser/6.1.2107.204 Safari/537.36'
}
html = requests.get(url, headers=header)
soup = BeautifulSoup(html.text, 'lxml')
all_src = soup.find_all('div', class_='viewmessage')
i2 = len(all_src)
for i in range(0, i2):
img_url = all_src[i].img['data-original']
html = requests.get(img_url, headers=header)
file_name = os.path.basename(img_url)
fp = open('./image/%s' % file_name, 'wb')
fp.write(html.content)
fp.close()
if __name__ == '__main__':
print("************************\n[*] 正在下载图片...")
start = time.time()
get_image()
end = time.time()
print("下载完成,共耗时:%f s" % (end - start))
|
END
单线程+300k左右的网速下载居然花了十多分钟。。。。。多线程后面再说吧^><^